Quantifying Ethical AI: How to Build Trustworthy Solutions
Ethics is making its way into the global AI race. As policy makers around the world draw up ethical principles for artificial intelligence, a question arises: How do we build and validate trustworthy AI in practice?
Blogpost by Martin Holm Jensen, Head of AI & Machine Learning, LEO Innovation Lab



Artificial intelligence is taking the world by storm and continues to expand the realm of possibilities in almost every industry. We increasingly rely on algorithms to fastrack our lives – from governance, healthcare, supply chains, transport, and banking, to the smartphone in your pocket citing your latest Netflix recommendation.
As AI becomes more prevalent, the ethical principles behind its development are more important than ever. As users, we all want to know that our privacy is protected, or that a platform works just as well for us regardless of our background or income. In short, we all want to trust the technology we’re inviting into our lives – but how can we be sure it’s trustworthy?
All about ethics
Ethics is the new battleground in the data-driven world where advances in AI have shifted the global discussion to a greater focus on how to wield this technology in ethically sound ways.
Competition Commissioner and Executive Vice-president for ‘Europe fit for the Digital Age’, Margrethe Vestager, recently promised Proposals on Artificial intelligence (AI) would be tabled within the first 100 days of her mandate with ethical and human-centred rules on AI. In April, the European Commission’s High-Level Expert Group on Artificial Intelligence released a set of guidelines for trustworthy AI. The guidelines can be broken into seven categories:
- Human agency and oversight
- Robustness and safety
- Privacy and data governance
- Transparency
- Diversity, non-discrimination and fairness
-
- Accountability
- Societal and environmental well-being
Each category marks an important consideration to how AI can be responsibly adopted into society. The big picture is that trustworthiness comes from all aspects of development. Each category requires a strong protocol for developing and validating algorithms. In particular, robustness and safety apply heavily to how we actually validate predictive models (e.g. neural networks).
Ethical versus good AI
From a development perspective, this raises an important question: What’s the difference between “an ethical AI” and “a good AI”? The latter is often quantified by metrics performed on test data that should reflect the actual data encountered when deployed. By virtue of moral philosophy, the former is a greater beast to address with numbers alone. Still, from an ethical perspective, some metrics do seem to be good candidates to insist on being measured when trustworthiness is sought.
Recently at LEO Innovation Lab, where I work, we had a paper published at MICCAI 2019, the International Conference on Medical Image Computing and Computer-Assisted Intervention. Among other things, it addresses the issue of robust artificial intelligence and how to build trust in automated solutions, which I’ll elaborate further on.
Digital solutions to improve well-being
Before proceeding, let me motivate why trustworthy AI is key to us here at LEO Innovation Lab. Our products seek to improve disease management for patients living with chronic skin conditions. A plethora of factors impact the well-being of these patients. One such is the low availability of dermatologists, which hinders their access to ongoing clinical support and causes them to wait months or years for the right diagnosis and treatment. This shortage of clinical experts is found even in the most developed healthcare systems.
Motivated by improving the patient journey for everyone, LEO Innovation Lab is aiming to build digital solutions that can assist and improve the journey for both doctors and patients; from discovering your first symptom to getting the right treatment and managing your disease.
Part of our product line uses features that require classifying dermatological content in images, such as detecting and locating symptoms of skin conditions in smartphone photos. We approach this problem using predictive models based on deep convolutional neural networks – and lots of data, of course. The classification AI is part of our endeavour to develop the capability for providing scalable skin diagnosis and skin condition management.
When is a weather forecast reliable?
Deploying products in healthcare raises the stakes compared to other sectors. After all, we’re dealing with people’s lives. When building AI-powered health solutions, this motivates the need for robust and stable predictions, simply because the domain is so sensitive. Getting back to the EU Commission’s guidelines, it’s stated that:
Trustworthy AI requires algorithms to be secure, reliable and robust enough to deal with errors or inconsistencies during all life cycle phases of AI systems.
But at what point is an algorithm reliable? And how should we validate when it’s deployed and live? The definition is too broad to answer in full, but I’ll shed light on one aspect of quantifying reliability. To this end, let’s zoom out a bit and consider the scenario of a weather forecast. Don’t worry, the same methodology applies to how we can measure reliability in deep neural networks used for photo classification.
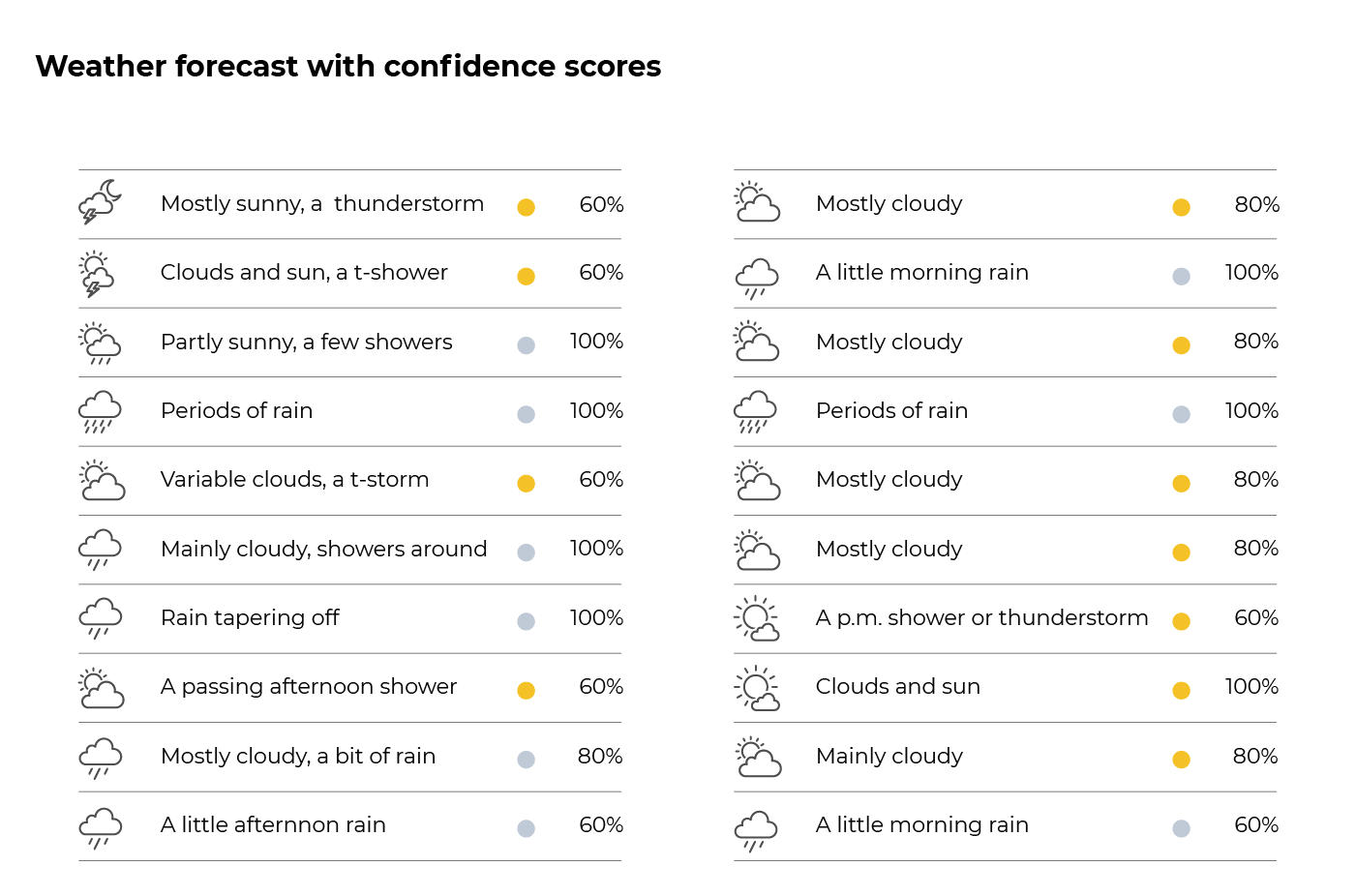
Consider the question Will it rain? – which you can see as a binary classification problem. In the example above, I took a 20-day forecast and used it to give such a prediction (answer) for each day. Grey means the prediction is Yes, it will rain, yellow that the prediction is No, it won’t rain. For each day, I also added a confidence score to reflect certainty of that prediction. This way, the forecast indicates what predictions should be most believed.
So time passes, and we learn that (for once) a forecast was correct in most cases as shown here:

We can calculate often cited values such as accuracy (90%), sensitivity (78%), and specificity (100%) – common statistics for binary classification problems. When these are high, we’d typically say: “That’s a good model!”
Confidence in prediction
What remains is to quantify how well the confidence scores were adjusted to the actual outcome. Intuitively, we want to capture that a wrong prediction is sometimes OK when the confidence score is 60%, less often OK when the score is 80%, and not OK when it’s 100%. More abstractly, we want that confidence scores reflect the actual likelihood of rain/no-rain being correctly predicted.
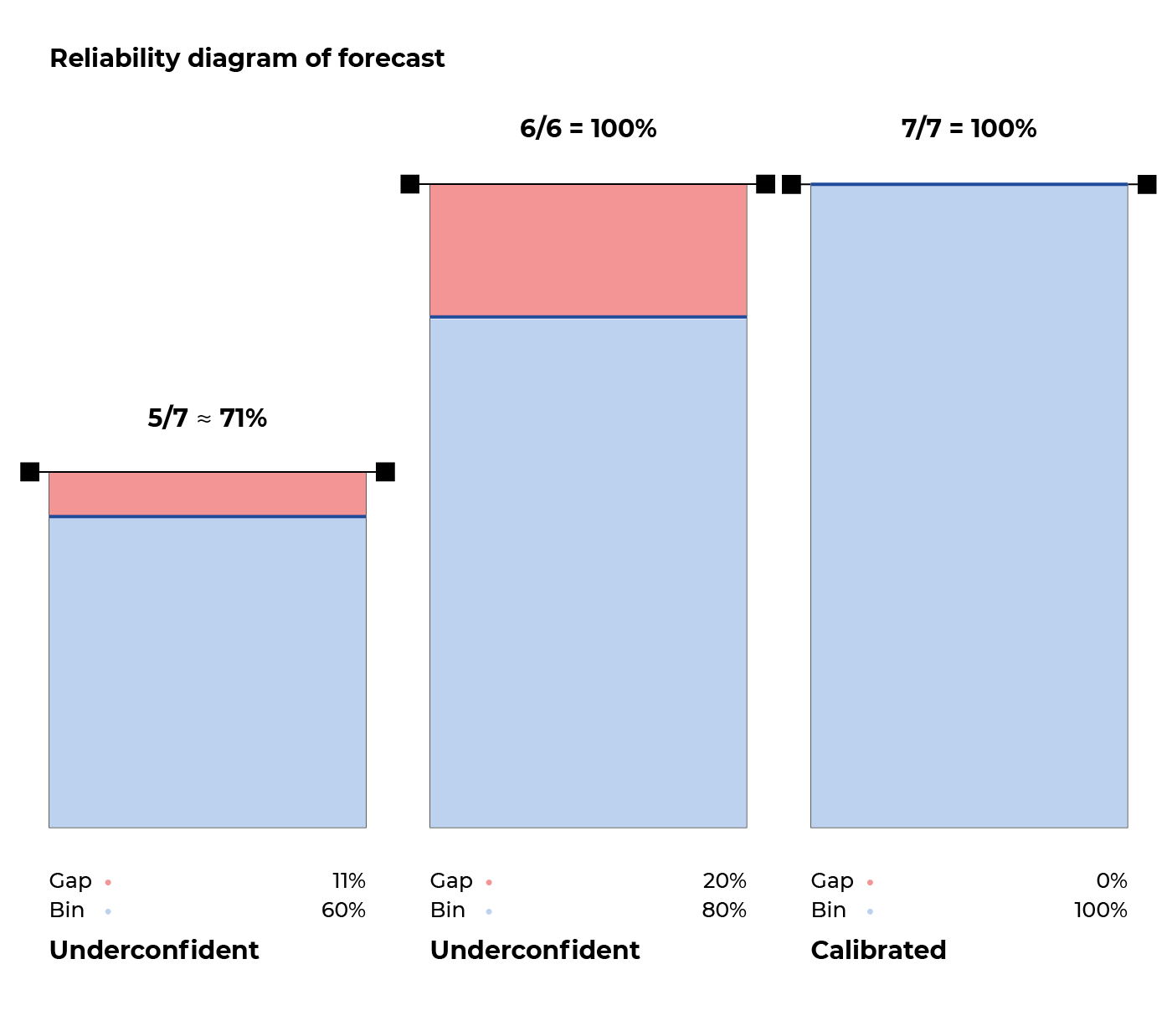
What we do is to look at predictions individually for each distinct value of confidence scores (60%, 80%, or 100%). So the well-calibrated forecast is correct on 71% of the seven 60%-cases; and all (100%) of the six 80%-cases and the seven 100%-cases. The graphic below illustrates this distribution of predictions into bins, based on whether the confidence score is 60%, 80%, or 100%.
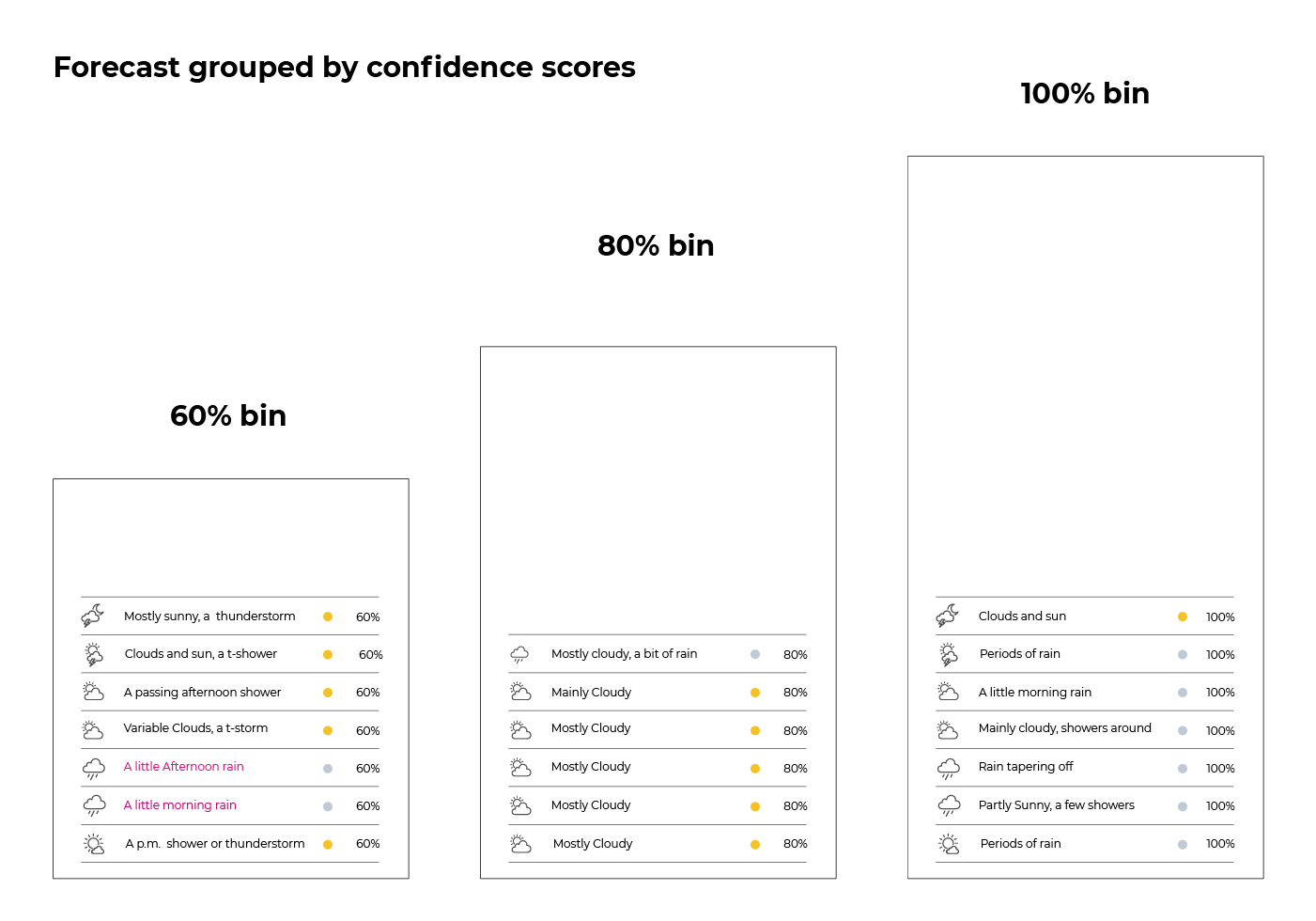
We then calculate accuracy on a per bin basis. The 100% bin is perfectly calibrated. That is, when the forecast gives a confidence score of 100%, it’s correct in all cases (100% of cases). For both the 60% and 80% bin, we see a higher accuracy than what the confidence scores suggest. In conclusion, the forecast is underconfident.
The situation can also be the opposite where we have a lower accuracy than what the confidence scores suggested, in which case the forecast is deemed overconfident. In either case, the receiver is presented with confidence scores that just don’t match how things actually work out – when you look at it over time. The consequence is a loss of trust in whoever made the forecast – with overconfidence often exacerbating the issue.
Confidence scores
To turn these observations into a single number, we use the gap between expected accuracy (confidence score mean) and actual accuracy inside a bin. Summing over the magnitudes of these gaps, we roughly have the expected calibration error (ECE) metric. This gives a single number for how well a model is calibrated in terms of accuracy. When the expected calibration error is low, confidence scores are therefore more reliable: They reflect the likelihood of the prediction being correct at the macro level.
High numbers in accuracy, sensitivity, and specificity are used to make the case that the predictor is good. What can we say about a low expected calibration error then? From the modelling perspective, it’s yet another important property to say the model is good. But if reliability is key to trust, then the expected calibration error is one of the metrics we should optimise for when building ethical AI.
We started out asking when a forecast is reliable and found that an analysis of confidence score and correctness could help answer that question. Next, I’ll establish the link between a weather forecast and the problem of detecting skin conditions in smartphone images. It’s the latter domain, which our MICCAI publication deals with.
Remedies for an overconfident model
At LEO Innovation Lab, one of our goals is to be able to leverage artificial intelligence to diagnose skin conditions from smartphone images. In this process, we released an internal prototype with one of our diagnostics classification models acting on the live camera feed of a smartphone.
Rather than the Yes/No question of the weather forecast, our prototype model predicts whether an image is one of four categories: clinically normal skin, psoriasis, dermatitis, or skin lesion (not psoriasis or dermatitis). It does so by giving a confidence score for the category it deems the image most likely to belong to. This means we can put the deep learning model through the same binning process as in the forecast scenario, calculating accuracy and expected calibration error.
However, when displaying confidence scores, our users of the prototype were not always impressed. The majority of the time, it came from the model being too overconfident; i.e. having too high confidence scores for what the users expected. In general, whether an underconfident model is preferable to an overconfident one depends on the usage, but for building trust, we find that overconfidence is the least conducive of the two.
Algorithmic tweak
While only being a prototype, we still wanted to remedy this behaviour and looked to academia for methods. We found that the reliability diagrams from the weather forecast scenario above would be suited to explore the issue, and the expected calibration error would be suited to quantify experiments in a single number. We also found an algorithmic tweak called label sampling in one of last year’s MICCAI papers: On the effect of interobserver variability for a reliable estimation of uncertainty of medical image segmentation.
In broad strokes, the above materials were used to experimentally show that, when you have multiple clinical assessments (labels) that are in disagreement for some image, a deep neural network will perform better, both in terms of accuracy and ECE, when it learns from all the assessments of that image – even if those assessments differ from what the majority may think.
Label sampling works
Below, you can find the reliability diagram for two differently trained neural networks. The left shows the results for our prototype model, the other for a model trained as the prototype but using the label sampling tweak mentioned above. The blue bar is the accuracy within a bin, the red area shows the gap to mean confidence score for that specific bin. In short, a smaller red area is what we’re after.
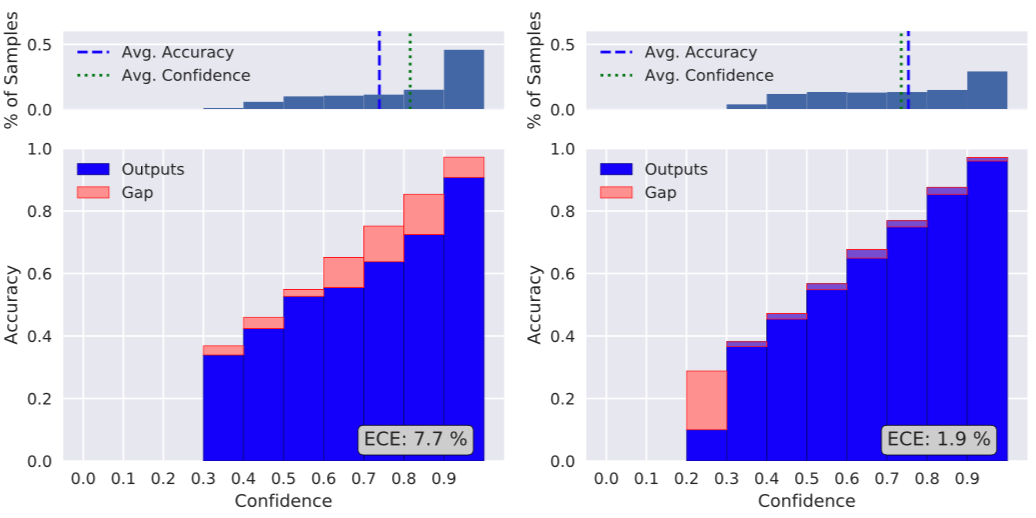
Recalling that small gaps means low expected calibration error, these reliability diagrams tell us:
- The prototype model is indeed overconfident.
- The tweak greatly improves model calibration (by a factor of four) giving us a more reliable model.
The improved model (right) is slightly underconfident, except in the 20%-30% bin where accuracy is less than 10%. In an actual product, we might want to avoid using any model prediction with less than 30% confidence score.
Both good and trustworthy
This is good because this more conservative model should alleviate the issue we found with our aforementioned prototype. This can also be seen from the fact that, whereas nearly half the predictions in the prototype have a confidence score above 90%, this share falls to about 1 in 4 on the right-hand side.
The shift is very pleasing for us model developers. It remedies (at least partly) the loss in trust from unrealistically high confidence scores. Moreover, it comes at no cost to other metrics we care about such as accuracy. In that way, we can optimise both for goodness (in terms of accuracy) and trustworthiness (in terms of ECE).
When is an AI algorithm trustworthy?
As already alluded to, a well-calibrated model is not enough to satisfy the very broad topic of trustworthiness. It also seems a bit of a stretch to call a forecast unethical for simply being wrong. But I’d posit it’s a relevant metric to keep track of during all life cycle phases of an algorithm, and in that way, it’s a technical way to assess reliability as required for trustworthy AI.
From a product perspective, questions of robustness and precise confidence scores are also relevant. In the domain of healthcare, the stakes are high and there’s a big difference in perception based on whether your doctor is 30% confident or 90% confident in her diagnosis. This is often exasperated when humans interact with machines, and so trustworthy products are a necessary condition for clinical adoption.
Well-calibrated models produce reliable confidence scores and can thereby improve trustworthiness. OurMICCAI publication shows a method for achieving this on real-world data. This leads us to conclude that we can, from a technical point of view, find an overlap between good and ethical models in that certain ethical aspects are quantifiable and relevant for metrics that assess model performance.
The formula for ethical AI
As I stated upfront regarding the EU guidelines, many ethical aspects we’ll never be able to quantify. This entails we won’t have a formula for ethical AI, but nor does the EU. These very top-level principles are a necessary starting point, but if they don’t turn operational (and pragmatic), they’re unlikely to matter for the development of ethical AI. This is where practitioners must help push for quantifiable aspects of model validation so as to shape the guidelines for technology adoption. We find the expected calibration error (when confidence scores are provided in any form) to be a highly relevant metric when we talk reliability and trustworthiness.
From gut feeling to quantifying ethical AI
Whether the EU guidelines will become more concrete remains to be seen. I hope to have made the case that we sometimes can find ways to quantify ethical AI. And we should, or ethical AI will be evaluated solely on gut feeling, which honestly goes against the principles (on the technical side) of building AI. In any case, model calibration and summary statistics alone don’t make for trustworthy AI. Many other pitfalls exist that could outright decrease trust.
On the technical side, this includes, but is certainly not limited to, instability towards small data perturbations, discrepancy between training data and actual data, or (worse) undiscovered data leakage. There’s still a long (perhaps never-ending) journey ahead to achieve ethical, trustworthy AI that is “secure, reliable and robust enough to deal with errors or inconsistencies during all life cycle phases of AI systems” – but I hope practitioners will help shape what this will mean in practice.






















